LLM - rozszyfrowujemy skrót
LLM to Large Language Model, czyli Duży Model Językowy. Nazwa mówi właściwie wszystko:
-
Large (Duży) - wytrenowany na ogromnych ilościach tekstu, ma miliardy parametrów
-
Language (Językowy) - zajmuje się językiem, tekstem, słowami
-
Model - matematyczna reprezentacja czegoś, w tym przypadku języka
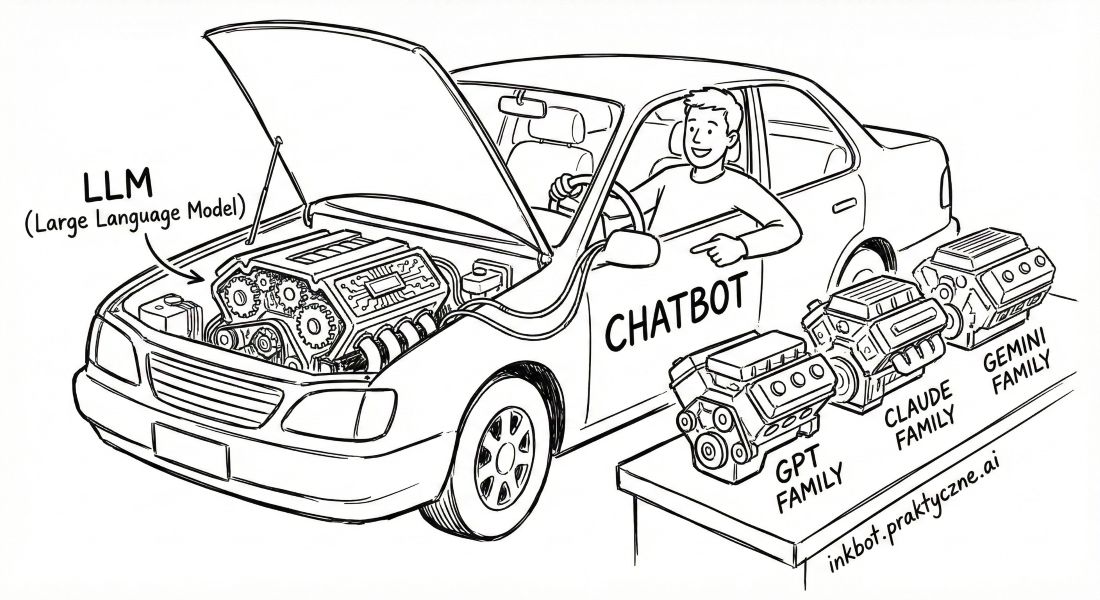
ChatGPT, Claude, Gemini - to wszystko interfejsy do rozmowy z LLM-ami. Sam model to silnik pod spodem. Chatbot to kierownica i pedały, które pozwalają Ci tym silnikiem sterować.
I tu ważna rzecz: jeden interfejs może korzystać z różnych modeli. To jak samochód, w którym możesz wymieniać silnik. ChatGPT daje ci dostęp do modeli z rodziny GPT (np. GPT-5.2 Instant, GPT-5.2 Thinking). Claude korzysta z modeli Anthropic (np. Sonnet, Opus). Gemini - z modeli Google (Gemini 3 Flash, Gemini 3 Pro).
Każdy producent ma w ofercie kilka modeli - szybsze i wolniejsze, prostsze i mocniejsze, tańsze i droższe. Z którym akurat rozmawiasz, zależy od wersji (darmowa/płatna) i twoich ustawień. Szczegółami zajmiemy się później - na razie wystarczy wiedzieć, że chatbot to nie to samo co model.
Uwaga: obecnie lista modeli jest już całkiem długa i powstają coraz to nowe. My skupimy się na zaledwie kilku, ale uwierz mi - to na start w zupełności wystarczy.
Autokorekta na sterydach
Znasz autokorektę w telefonie? Zaczynasz pisać "Będę za pięć mi..." i telefon podpowiada "minut". Skąd wie? Bo tysiące razy widział, że po "za pięć" ludzie piszą "minut".
LLM działa na tej samej zasadzie, tylko w kosmicznie większej skali. I z jednym istotnym dodatkiem: wagami.
Wyobraź sobie gigantyczną pajęczynę, w której każde słowo jest połączone z innymi słowami. Te połączenia mają różną grubość - czyli wagę. Słowo "pies" ma grube połączenie ze słowem "szczeka", cieńsze ze słowem "futro", jeszcze cieńsze ze słowem "samochód".
Kiedy LLM generuje tekst, nie rzuca kostką. Patrzy na te połączenia i ich wagi. Po słowach "Pies głośno..." model widzi, że najgrubsze połączenie prowadzi do "szczeka". Ale "warczy" też ma solidną wagę. "Śpiewa" - znacznie cieńszą. "Programuje" - prawie zerową.
Model wybiera słowo, uwzględniając te wagi. Dlatego pies częściej szczeka niż programuje. Ale tu jest haczyk: model nie wybiera zawsze najgrubszego połączenia. Dodaje odrobinę losowości. Dzięki temu nie dostaniesz identycznej odpowiedzi za każdym razem, a teksty brzmią naturalnie, nie mechanicznie.
Podczas treningu model czyta miliardy tekstów i cały czas dostosowuje te wagi. Widzi zdanie "Kot siedzi na..." i sprawdza co dalej. "Kanapie"? Wzmacnia połączenie. "Chmurze"? Osłabia. Po miliardach takich korekt powstaje pajęczyna, która całkiem nieźle odwzorowuje jak ludzie używają języka.
Piszesz: "Napisz mi przepis na sernik"
LLM nie sięga do bazy przepisów. Nie "wie" co to sernik w sensie, w jakim ty wiesz. Ale jego pajęczyna połączeń zna wzorce. Po słowach "przepis na sernik" grube nici prowadzą do składników, potem do sposobu przygotowania, potem do temperatury pieczenia. Model podąża tymi połączeniami i generuje tekst, który pasuje do wzorca.
Trening, czyli czytanie internetu
Skąd LLM wie te wszystkie rzeczy? Z treningu. Zanim zaczął odpowiadać na pytania, przeczytał internet. Nie cały, ale sporą jego część - książki, artykuły, Wikipedię, fora, dokumentacje techniczne, przepisy, wiersze, instrukcje obsługi, kłótnie pod postami.
Wyobraź sobie studenta, który przed egzaminem nie uczył się z podręcznika, ale przeczytał tysiące gotowych odpowiedzi na pytania egzaminacyjne. Nie rozumie przedmiotu tak jak profesor, ale zna wzorce. Wie jak wyglądają dobre odpowiedzi. Potrafi złożyć słowa tak, żeby brzmiały sensownie.
LLM to taki student - przeczytał wszystko, zapamiętał wzorce, nauczył się je odtwarzać. Robi to lepiej niż jakikolwiek człowiek, bo przeczytał więcej niż jakikolwiek człowiek kiedykolwiek przeczyta.
Jak model "rozumie" polecenia
Krótka odpowiedź: nie rozumie. Rozpoznaje wzorce.
Kiedy piszesz "Napisz mi wiersz o kocie", model nie myśli: "Aha, użytkownik chce wiersz, temat to kot, muszę uruchomić moduł poetycki". Nic z tych rzeczy.
Model widzi sekwencję słów i szuka w swojej pajęczynie połączeń: co zwykle następuje po takim tekście? Podczas treningu widział miliony razy sekwencje w stylu "Napisz wiersz o..." po których następował wiersz. Nauczył się, że po takim wzorcu powinien generować tekst wierszowany, z rymami, metaforami, odpowiednim rytmem.
To trochę jak kelner w restauracji. Słyszy "poproszę schabowego z frytkami" i przynosi schabowego z frytkami. Nie dlatego, że rozumie twoją potrzebę zaspokojenia głodu ani filozofię schabowego. Po prostu tysiące razy słyszał takie zdanie i wie, co po nim następuje - trip do kuchni i talerz z kotletem.
Dlaczego to ważne? Bo sposób w jaki sformułujesz polecenie ma znaczenie. "Napisz wiersz" i "Jesteś poetą. Stwórz liryczny utwór" to dla modelu różne wzorce, które mogą prowadzić do różnych wyników. Pierwszy jest prosty i bezpośredni. Drugi aktywuje połączenia związane z "poetą" i "liryką" - model może wygenerować coś bardziej wysublimowanego.
To dlatego istnieje coś takiego jak prompt engineering - sztuka formułowania poleceń. Nie dlatego, że model lepiej "rozumie" jedne słowa niż inne. Dlatego, że różne słowa aktywują różne ścieżki w pajęczynie połączeń.
Parametry - nie musisz wiedzieć, ale...
W artykułach o AI zobaczysz często informacje typu "model ma 70 miliardów parametrów" albo "model ma 1,5 biliona parametrów". Co to znaczy?
W największym uproszczeniu: parametry to pokrętła, które model ustawia podczas treningu. Im więcej pokręteł, tym dokładniej może odwzorować wzorce z danych treningowych. Więcej parametrów zazwyczaj oznacza mądrzejsze odpowiedzi, ale też wolniejsze działanie i wyższe koszty.
Nie musisz rozumieć tego głębiej. Wystarczy wiedzieć, że jak ktoś mówi "większy model", to zwykle znaczy "droższy, wolniejszy, ale potencjalnie lepszy".
Dlaczego czasem gada bzdury
Skoro LLM tylko przewiduje następne słowo, to ma pewien fundamentalny problem: nie wie co jest prawdą. Wie tylko co jest prawdopodobne.
Pytasz: "Kto napisał Pana Tadeusza?"
LLM odpowiada: "Adam Mickiewicz" - bo w tysiącach tekstów te słowa występują razem.
Pytasz: "Kto napisał 'Tajemnice Wawelu' w 1847 roku?"
LLM może odpowiedzieć z pełnym przekonaniem, podając autora, wydawnictwo i szczegóły - mimo że taka książka nigdy nie istniała. Bo wzorzec "autor + tytuł + rok + wydawnictwo" jest mu znany. Wypełnia go sensownie brzmiącymi danymi.
To się nazywa "halucynacja" i to największa pułapka w pracy z LLM-ami. Model nie odróżnia faktów od fikcji. Generuje tekst, który pasuje do wzorca. Czy wzorzec jest zgodny z rzeczywistością? To już nie jego działka.
Token - słowo, które usłyszysz
Jeszcze jeden termin, który warto znać: token. LLM nie myśli słowami, tylko tokenami - kawałkami tekstu. Słowo "kot" to jeden token. Słowo "konstantynopolitańczykowianeczka" to kilka tokenów. Spacja to token. Znak interpunkcyjny to token.
Dlaczego to ważne? Bo limity w chatbotach są liczone w tokenach. Jak dostajesz informację "możesz wysłać 8000 tokenów" - to mniej więcej 6000 słów po polsku. Polski język potrzebuje więcej tokenów niż angielski, bo ma więcej odmian i dłuższe słowa.
W praktyce nie musisz liczyć tokenów. Wystarczy wiedzieć, że istnieją i że długie rozmowy w końcu natrafiają na limit.
Czarna skrzynka (Black box)
W przypadku LLM możesz spotkać się z określeniem “czarna skrzynka” (black box).
Termin pochodzi z inżynierii. Czarna skrzynka to urządzenie, do którego coś wchodzi i coś wychodzi, ale nie widzisz co dzieje się w środku. Nie dlatego, że ktoś przed tobą ukrywa - po prostu środek jest zbyt skomplikowany do ogarnięcia.
Duży model językowy ma miliardy parametrów. Miliardy połączeń z wagami, które ustalił sam podczas treningu. Nawet twórcy modelu nie są w stanie powiedzieć "ten konkretny parametr odpowiada za rozpoznawanie sarkazmu" albo "to połączenie sprawia, że model wie kim był Mickiewicz". Te wzorce są rozproszone po całej pajęczynie w sposób, którego nikt nie projektował i nikt do końca nie rozumie.
Co to oznacza w praktyce?
Przede wszystkim: brak powtarzalności. Zadaj modelowi to samo pytanie trzy razy - możesz dostać trzy różne odpowiedzi. Nie dlatego, że model jest zepsuty. Pamiętasz losowość, o której pisałem wcześniej? Model nie wybiera zawsze najgrubszego połączenia w pajęczynie. Rzuca kostką - ważoną, ale wciąż kostką. Przy pierwszym rzucie wypadnie "szczeka", przy drugim "warczy", przy trzecim znowu "szczeka".
Dla kogoś przyzwyczajonego do komputerów, które zawsze dają ten sam wynik dla tych samych danych, to może być frustrujące. Kalkulator zapytany o 2+2 nie odpowie raz 4, a raz 4,1. LLM zapytany o stolicę Polski odpowie zawsze "Warszawa" - ale zapytany o przepis na sernik da ci za każdym razem trochę inny przepis. Czasem lepszy, czasem gorszy.
Dlatego warto traktować odpowiedzi LLM-a jak propozycje, nie wyroki. Nie podoba ci się odpowiedź? Zapytaj jeszcze raz. Albo przeformułuj pytanie. Czarna skrzynka może za drugim razem wyrzucić coś lepszego.
Czasem model odpowie błędnie i nikt nie potrafi wyjaśnić dlaczego. Czasem odpowie genialnie - i też nikt nie wie dlaczego akurat tak. Model nie ma "trybu debugowania", w którym pokazuje tok rozumowania.
To nie wada - to cecha technologii. I warto o niej pamiętać.
Okno kontekstowe, czyli pamięć złotej rybki
Sam LLM nie pamięta poprzednich rozmów z tobą. Każda sesja to dla niego czysta karta. Ale uwaga: chatboty to coś więcej niż sam model. Nowoczesne interfejsy jak ChatGPT czy Claude mają dodatkowe mechanizmy pamięci - mogą zapisywać informacje o tobie i wczytywać je przy kolejnych rozmowach. To nie model pamięta - to aplikacja wokół niego podrzuca mu notatki "z kim rozmawiasz i co już wiesz".
Nawet z tymi mechanizmami, w ramach pojedynczej rozmowy model ma ograniczenia. Pamięta bieżącą konwersację tylko "do pewnego momentu". To "do pewnego momentu" nazywa się oknem kontekstowym.
Wyobraź sobie, że rozmawiasz z kimś przez wąskie okno. Podajesz mu kartki z tekstem, on odpowiada. Ale okno ma ograniczoną szerokość - mieści tylko określoną liczbę kartek. Kiedy wrzucasz nowe, najstarsze wypadają z drugiej strony. Osoba po drugiej stronie widzi tylko to, co aktualnie mieści się w oknie.
Tak właśnie działa LLM. Okno kontekstowe to limit tekstu, który model "widzi" podczas generowania odpowiedzi. Obejmuje wszystko: twoje pytania, odpowiedzi modelu, wrzucone dokumenty, instrukcje systemowe. Kiedy rozmowa przekracza limit, początek znika. Model zwyczajnie nie widzi, o czym rozmawialiście na początku.
Jak duże jest to okno? Zależy od modelu. Mierzy się je w tokenach (pamiętasz - kawałkach tekstu). Starsze modele miały okna 4 000-8 000 tokenów - kilka stron A4. Nowsze mają 128 000, a niektóre nawet milion tokenów. To już kilkaset stron tekstu.
Brzmi dużo? W praktyce zaskakująco szybko się kończy. Wrzucasz 30-stronicowy raport, zadajesz kilka pytań, model odpowiada - i nagle jesteś przy granicy. Model zaczyna "zapominać" co było na początku raportu.
Praktyczne konsekwencje:
-
Długa rozmowa? Model może zapomnieć ustalenia z początku.
-
Wrzucasz duży dokument? Może nie zmieścić się cały.
-
Model nagle "głupieje" w trakcie rozmowy? Pewnie właśnie wypadło mu coś istotnego z okna.
Kiedy czujesz, że model gubi wątek, czasem lepiej zacząć nową rozmowę i streścić najważniejsze ustalenia, niż ciągnąć starą. Zajmiemy się tym bardziej szczegółowo w dalszej części kursu.
Multimodalność - AI to nie tylko tekst
Do tej pory pisałem głównie o tekście (na nim operują LLM'y), ale nowoczesne chatboty potrafią więcej - rozumieją obrazy, generują grafiki, a niektóre radzą sobie z dźwiękiem i wideo. To zjawisko nazywa się multimodalnością.
Multi = wiele. Modalność = sposób przekazu (tekst, obraz, dźwięk). Multimodalny model to taki, który obsługuje więcej niż jeden sposób.
Co potrafią multimodalne chatboty:
Analizować obrazy - wrzucasz zdjęcie, pytasz "co tu widzisz?" i dostajesz opis
Czytać tekst ze zdjęć - fotografujesz dokument, menu w restauracji, tablicę informacyjną
Rozumieć wykresy i diagramy - wrzucasz wykres sprzedaży, pytasz o trendy
Generować obrazy - opisujesz co chcesz zobaczyć, dostajesz grafikę
ChatGPT, Claude i Gemini - wszystkie trzy potrafią analizować obrazy. Generowanie grafik to inna sprawa. Claude grafik nie generuje - skupia się na tekście. Pozostałe dwa posiadają modele, które generują obrazy.
Generowanie grafiki - to osobna bajka
Kiedy prosisz ChatGPT o narysowanie "kota w kosmosie", nie robi tego ten sam model, który pisze teksty. Pod spodem odpala się osobny model - w przypadku ChatGPT może to być GPT-Image-1.5. Chatbot tylko przekazuje twoje polecenie i odbiera wynik.
Modele graficzne działają na podobnej zasadzie co językowe - uczą się wzorców. Tyle że zamiast przewidywać następne słowo, przewidują jak powinien wyglądać obraz pasujący do opisu. Podczas treningu widziały miliony par "opis + obrazek" i nauczyły się tych zależności.
Generowaniu obrazów poświęcę oddzielny rozdział.
Podsumowanie
-
LLM to Large Language Model - silnik do generowania tekstu.
-
Chatbot (ChatGPT, Claude) to interfejs do rozmowy z LLM-em.
-
LLM przewiduje następne słowo na podstawie wzorców z treningu.
-
Trening = przeczytanie miliardów tekstów z internetu, ale nie tylko to.
-
LLM nie wie co jest prawdą - wie co jest prawdopodobne.
-
Stąd halucynacje: odpowiedzi brzmiące sensownie, ale zmyślone.
-
Token to jednostka tekstu, w której na przykład liczone są limity okna kontekstowego.
-
Okno kontekstowe to limit tego, ile tekstu model "widzi" podczas rozmowy.
-
Multimodalność to zdolność AI do pracy z różnymi formatami: tekstem, obrazami, dźwiękiem - nowoczesne chatboty potrafią analizować zdjęcia, a niektóre generują grafiki.
Dla dociekliwych: Trening to nie tylko czytanie
Pisałem wcześniej, że model "przeczytał internet". To prawda, ale uproszczona. Stworzenie chatbota to proces, który może odbywać się w kilku etapach, nie jedno wielkie czytanie.
Niektóre z nich to:
Czytanie (pre-training)
Model czyta miliardy tekstów - książki, artykuły, Wikipedię, fora, dokumentacje. Na tej podstawie buduje pajęczynę połączeń między słowami. Po tym etapie model umie generować tekst, który brzmi sensownie, ale jest jak dziecko nauczone mówić przez telewizor - gada płynnie, ale nie wie co wypada, a co nie.
Nauka dobrych manier (fine-tuning)
Surowy model trzeba nauczyć, jak odpowiadać na pytania w pomocny sposób. Dostaje przykłady: "Jak użytkownik zapyta o X, dobra odpowiedź wygląda tak". Tysiące takich przykładów. Model się dostraja.
Uczenie od ludzi (RLHF)
RLHF to Reinforcement Learning from Human Feedback - uczenie ze wzmocnieniem na podstawie opinii ludzi. Model generuje kilka odpowiedzi na to samo pytanie. Ludzie oceniają która lepsza. Model uczy się, że pewne style odpowiedzi są preferowane - rzeczowe zamiast chaotycznych, bezpieczne zamiast kontrowersyjnych, pomocne zamiast wymijających.
To dlatego ChatGPT nie zachowuje się jak losowy tekst z internetu, mimo że na takim trenował. RLHF to taki kurs wychowawczy - model uczy się czego ludzie od niego oczekują.
Nie musisz tego pamiętać, żeby skutecznie używać chatbotów. Ale jeśli kiedyś zastanawiałeś się, dlaczego model odmawia pewnych rzeczy albo przeprasza częściej niż trzeba - teraz wiesz. Ktoś go tak wytrenował.