
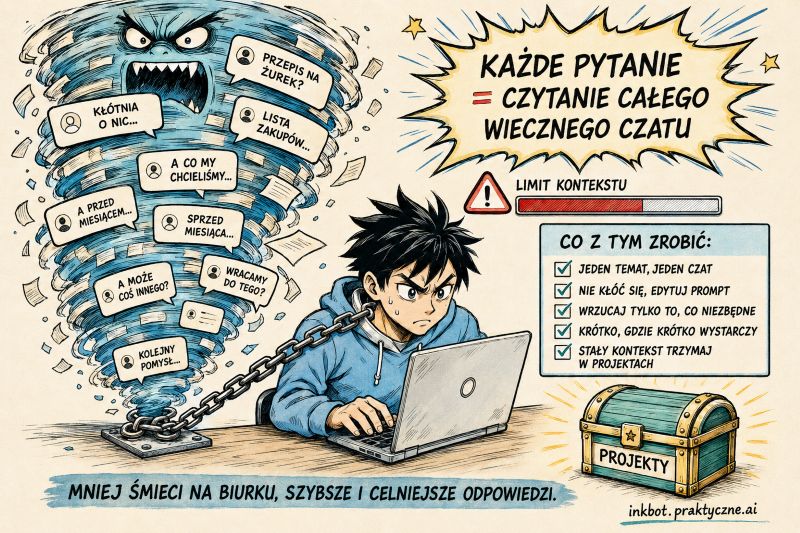
Masz jeden czat. Siedzi w nim wszystko. Pomysły na firmę, przepis na żurek, kłótnia o to, czy "wziąć" pisze się przez "ść", plan urlopu i prośba o sprawdzenie umowy. Trzy tysiące wiadomości w miesiąc, wszystkie w tym samym oknie. I dziwisz się, że AI ostatnio gorzej kojarzy.
Zacznijmy od mechaniki, bo bez niej reszta nie ma sensu. Chatbot nie pamięta Waszej rozmowy tak, jak Ty ją pamiętasz. On nie ma "pamięci" w ludzkim sensie. Przed każdą pojedynczą odpowiedzią czyta od nowa CAŁY czat. Od pierwszej wiadomości do ostatniej.
To trochę tak, jakby Twój kolega przed odpowiedzią na pytanie "która godzina" musiał na głos przeczytać sobie Waszą całą korespondencję z ostatnich trzech tygodni. Z żurkiem i kłótnią o "ść" włącznie. Za każdym razem. Im dłuższy czat, tym dłużej czyta i tym więcej mu się miesza.
Ta "pamięć", w którą chatbot patrzy, ma swoją nazwę: okno kontekstowe. I ma dwie wredne właściwości.
Pierwsza: kosztuje. Jeśli korzystasz z Claude, każda wiadomość przepala Twój limit proporcjonalnie do tego, ile tekstu model musi przeczytać. Wieczny czat na 3000 wiadomości to wieczne czytanie 3000 wiadomości. Twój limit znika, a Ty nawet nie wiesz dlaczego.
Druga, gorsza: model w długim oknie głupieje. Brzmi jak ezoteryka, ale jest zmierzone. Kiedy ważna informacja siedzi gdzieś w środku gigantycznej rozmowy, model gubi ją częściej niż tę z początku albo z końca. Badacze nazwali to "lost in the middle". Po polsku: zgubił się w środku, jak Ty w IKEA. To się tyczy nie tylko Claude, ale każdego chatbota opartego o LLM.
Dobra wiadomość jest taka, że na każdy z tych problemów jest prosty nawyk. Oto osiem.
Wieczny czat to cyfrowe zbieractwo
Pierwszy nawyk, który zmieni Ci życie: jeden temat, jeden czat. Skończyłeś pisać ofertę? Zamknij. Zaczynasz planować urlop? Nowy czat. Nie ciągnij jednej rozmowy przez miesiąc jak gumę do żucia, którą żujesz od poniedziałku.
Ludzie trzymają wszystko w jednym oknie z tego samego powodu, z którego niektórzy trzymają w piwnicy słoiki z 2009 roku. "A bo może się przyda". Nie przyda się. AI nie potrzebuje Twojego przepisu na żurek, żeby pomóc Ci z fakturą. A czytać go i tak będzie, bo leży na wierzchu.
Nie kłóć się z promptem. Popraw go.
Najbardziej niedoceniana funkcja w całym "AI" to mały ołówek przy Twojej wiadomości. Edycja.
Sytuacja, którą znasz. Napisałeś prompt, AI odpowiedziało nie tak. Co robisz? Piszesz "nie, nie o to mi chodziło, miałem na myśli...". AI próbuje znowu. Dalej źle. "No nie, bardziej tak, żeby...". I tak pięć razy. Po pięciu rundach Twój czat to protokół kłótni, a model brnie w tym bałaganie coraz głębiej, bo całą wymianę nosi ze sobą.
Zamiast tego cofnij się do poprzedniego prompta, kliknij ołówek i napisz go od nowa, lepiej. Czat rozgałęzia się od tego momentu, a cała nieudana wymiana znika z kontekstu. Model dostaje czystą kartkę i jedno dobre polecenie zamiast pięciu poprawek do złego. To jak cofnięcie taśmy zamiast tłumaczenia aktorowi, dlaczego poprzednie pięć dubli było do bani.
W skrócie: jeżeli prompt ewidentnie nie dał Ci żadnego ważnego wyniku to użyj opcji edycji, nie dopytuj.
Każ mu się streszczać
Domyślnie chatbot gada jak wujek na imieninach. Pytasz o jedną rzecz, dostajesz wstęp, trzy akapity, podsumowanie i ofertę dalszej pomocy. Ten potok kosztuje podwójnie: Twój czas teraz i Twój limit później, bo cały zostaje w czacie i model przeczyta go przy każdej następnej wiadomości.
Więc mu powiedz. "Odpowiedz jednym zdaniem." "Sama liczba, bez tłumaczenia." "Krótko, w punktach, bez wstępu." Tam, gdzie potrzebujesz odpowiedzi, a nie wypracowania, krótka odpowiedź oszczędza limit teraz i kontekst później. Wypracowanie zostaw na sytuacje, w których faktycznie go chcesz.
Konkret. Pytasz "ile to VAT od 4200 zł". Chcesz usłyszeć "966 zł", a nie wykład o stawkach, historii podatku i trzech metodach liczenia. Dopisujesz "sama kwota" i masz samą kwotę. Pomnóż to przez sto pytań w tygodniu i z drobiazgu robi się realna różnica w limicie.
Wrzucaj tylko to, co niezbędne
Pokusa jest zawsze ta sama: mam folder z dwunastoma plikami, wrzucę wszystkie, niech AI sobie wybierze. Nie wybierze dobrze. Wrzucasz dwanaście plików, model brodzi w dwunastu plikach, a Ty potrzebowałeś jednego akapitu z trzeciego.
Zanim coś wrzucisz, zadaj sobie pytanie: czy do tego konkretnego zadania to jest naprawdę potrzebne? Często wystarczy wkleić jeden fragment zamiast całego raportu na 80 stron. Im mniej szumu wrzucisz, tym celniej AI trafi i tym mniej zapłacisz.
To jak wysłanie kogoś po mleko i wręczenie mu przy okazji całej listy zakupów z zeszłego miesiąca. Wróci z mlekiem, ale później i z trzema rzeczami, o które nikt nie prosił.
txt i markdown biją PDF-a i Worda
Ten sam tekst możesz dać AI w pięciu formatach i każdy kosztuje inaczej. Najtaniej i najczyściej: zwykły txt i markdown. Najgorzej: PDF i Word.
Powód jest prozaiczny. PDF, Word i jeszcze kilka innych formatów ciągną za sobą worek formatowania, którego AI nie potrzebuje. TXT i markdown to czysty tekst, bez ozdóbek i bez śmieci. Model czyta to od razu, a Ty nie płacisz za tabelki i nagłówki, których w treści i tak nie widać.
Praktyka: jeśli możesz, zapisz albo skopiuj treść jako txt lub markdown, zanim ją wrzucisz. Z PDF-a wyklej sam tekst. Brzmi jak dłubanina, ale to dziesięć sekund, które oszczędzają i limit, i błędy. Możesz skorzystać z darmowych narzędzi konwertujących pliki do formatu markdown.
Najtrudniejszy wariant dla modelu to tekst wrzucony jako zdjęcie albo skan. Wtedy AI musi najpierw rozszyfrować obrazek, a dopiero potem przeczytać treść. Dwa razy więcej roboty i dwa razy więcej miejsca na to, żeby coś przekręcić. Jeśli masz tekst, daj tekst, nie fotkę tekstu.
Wrzucił plik i pisze: "przeanalizuj sobie"
Klasyk gatunku. Wrzucasz plik, dopisujesz "przeanalizuj sobie" i czekasz. AI coś analizuje. Tylko nie wiadomo co, bo nie powiedziałeś. Streszcza? Szuka błędów? Wyciąga dane? Ocenia styl? Strzela na oślep i zwykle trafia obok. Więc piszesz drugą wiadomość: "To jak już się zapoznałeś to teraz wyciągnij mi....". I dopiero teraz AI robi to, czego chciałeś od początku, ale mimo tego, że już przecież przeczytało plik to robi to jeszcze raz.
Policzmy. Pierwsza odpowiedź poszła do kosza, ale w czacie została. Druga wiadomość też kosztowała. Zmarnowałeś dwie rundy na coś, co dało się zrobić w jednej. Wrzucaj plik razem z konkretnym poleceniem: "Z tego pliku wypisz mi same kwoty z trzeciej tabeli, w punktach". Jedna wiadomość, jeden cel, zero zgadywanki. Ważne! Jeżeli będziesz pytał o coś jeszcze to nie wrzucaj tego samego pliku ponownie. On już jest w kontekście, AI i tak go przeczyta. Jak wrzucisz drugi raz to przeczyta dwa razy.
Niech najpierw zapyta
Czasem po prostu nie wiesz, jakich informacji model potrzebuje do zadania. Więc dajesz na czuja, on robi coś obok, Ty poprawiasz, on znowu obok. I lądujesz w tym samym błędnym kole poprawek, o którym już była mowa.
Jest na to ruch wyprzedzający. Dopisz do polecenia jedno zdanie:
Chcę, żebyś wykonał zadanie polegające na [tu zadanie]. Zanim zaczniesz, zapytaj mnie o wszystko, czego potrzebujesz, żeby zrobić to jak najlepiej.
Role się odwracają. Teraz to model odwala robotę z dopytywaniem. Wyrzuca z siebie trzy, cztery pytania, Ty odpowiadasz na nie w jednej wiadomości i dopiero wtedy puszczasz go do dzieła. Dostaje komplet za jednym zamachem i trafia od razu.
To jak rozmowa z fachowcem. Ten kiepski bierze się do roboty, a o wymiary pyta, jak już położył połowę kafelków. Dobry najpierw siada, wypytuje o wszystko, a wiertarkę włącza na końcu.
Premia dla kontekstu jest oczywista. Zamiast pięciu rund poprawek, które puchną w czacie i które model wlecze ze sobą przy każdej odpowiedzi, masz jedną wymianę pytań i jedną porządną odpowiedź. Mniej śmieci w oknie, mniej spalonego limitu, mniej Twojej krwi.
Uwaga! Na pewno dobrze działa w Claude. Te mniej rozbudowane chatboty mogą sobie z tym nie poradzić.
Grzecznościowy ping-pong
Jesteś miłym człowiekiem. To się chwali. Tylko AI tego nie potrzebuje, a każda taka wymiana to osobna runda doklejona do czatu.
"Dzień dobry!" "Dzień dobry, w czym mogę pomóc?" "Mam takie pytanie." "Jasne, śmiało!" "No więc...". Trzy rundy i jeszcze nie padło pytanie. Chatbot nie obrazi się, że przeszedłeś do rzeczy. Nie napisze o Tobie na Facebooku, że jesteś gburem. Zadaj pytanie od razu, z konkretem. "Dziękuję, do widzenia" na koniec też możesz sobie darować, model i tak nie odprowadzi Cię do drzwi. Jak znajdziesz w Internecie legendy o tym, że bycie miłym robi różnice, to jest to prawda. Ale nie powoduje, że chatbot lepiej Ci odpowie. Co najwyżej dostosuje się do Twojego tonu.
Streść i zacznij od nowa
Czasem długiego czatu nie da się uniknąć. Rozkręciłeś poważny temat, model już zna kontekst, połowa rzeczy jest dograna i głupio zaczynać od zera. A czat puchnie i zwalnia.
Trik: poproś o streszczenie. "Streść naszą rozmowę tak, żebym mógł kontynuować w nowym czacie. Wypisz ustalenia, decyzje i to, na czym stanęliśmy." Dostajesz zwięzłą notkę. Otwierasz nowy czat, wklejasz ją na start i jedziesz dalej. Cały balast trzech tysięcy wiadomości zostaje za Tobą, a model dostaje to, co naprawdę potrzebne, w trzech akapitach zamiast w trzydziestu ekranach.
To jak przesiadka do czystego auta zamiast wożenia ze sobą wszystkich paragonów, kubków po kawie i piasku z wakacji sprzed roku.
Projekty: kontekst raz, czaty na zawsze
Jeśli wracasz do tego samego tematu regularnie, przestań za każdym razem tłumaczyć AI, kim jesteś i nad czym pracujesz. Od tego są Projekty, w Claude i w ChatGPT.
Działa to tak: raz wrzucasz do projektu materiały i instrukcje. Kim jesteś, jak masz pisać, jakie pliki są stałym tłem. Potem każdy nowy czat w tym projekcie startuje już z tą wiedzą. Nie wklejasz jej w kółko, nie nosisz w każdym oknie. Dzięki temu możesz otwierać świeże czaty bez bólu, bo cały kontekst, na którym Ci zależy, czeka na poziomie projektu, a nie w jednej zajechanej rozmowie.
Sprzątaj biurko, nie buduj strychu
Cała ta robota sprowadza się do jednego nawyku: traktuj kontekst jak miejsce na biurku, nie jak strych. Kładziesz na blat tylko to, na czym pracujesz teraz. Resztę odkładasz na miejsce. AI odwdzięczy Ci się szybszymi i celniejszymi odpowiedziami, a Twój limit przestanie znikać w niewyjaśnionych okolicznościach.

