
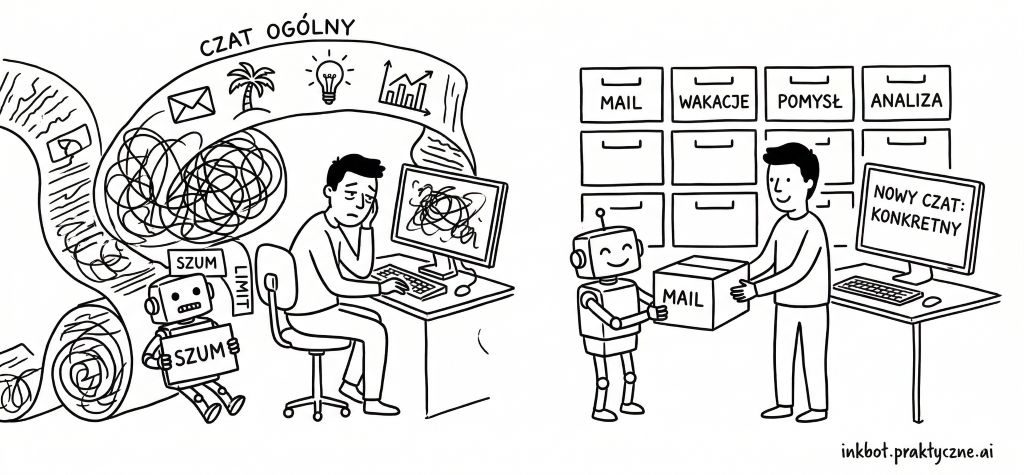
Prawie każdy, kto korzysta z Claude na co dzień, zna ten moment. Piszesz, rozmawiasz, dobrze Ci idzie i nagle limit. Koniec zabawy. Wracaj za godzinę, albo trzy.
Problem zwykle nie leży w tym, że za dużo pytasz. Problem leży w tym, jak pytasz.
Kontekst to waluta, nie powietrze
Użytkownicy często traktują okno kontekstowe jak nieskończony notatnik. Wklejają całe dokumenty, prowadzą rozmowy po 40 wiadomości, trzymają w jednym czacie wszystko - od debugowania kodu po planowanie wakacji.
Tymczasem każdy token, który wysyłasz do modelu, kosztuje. Nie tylko pieniądze (na API), ale przede wszystkim jakość odpowiedzi i limity w Claude.ai. Im dłuższa konwersacja, tym model ma więcej szumu do przebrnięcia i tym szybciej spalasz swój przydział.
Proste porównanie: jeden dobrze sformułowany prompt z kontekstem 500 tokenów da ci lepszą odpowiedź niż dziesiąta wiadomość w konwersacji, która ma już 50 tysięcy tokenów w tle.
Zasada numer jeden: nowe zadanie, nowy czat
To brzmi banalnie, ale większość osób tego nie robi. Prowadzą jeden czat jak dziennik pokładowy. Debugowanie SQL? Ten sam czat. Pomysł na post na LinkedIn? Ten sam czat. Analiza raportu sprzedażowego? Naprawdę tak się dzieje.
Każda nowa konwersacja startuje z czystym kontekstem. Model nie musi przebijać się przez historię twoich poprzednich pytań i własnych odpowiedzi. Dostajesz pełną uwagę na to, co ważne teraz.
Praktyczna reguła: jeśli nowe pytanie nie wymaga wiedzy z poprzednich wiadomości - otwórz nowy czat. Zawsze.
Przestań wklejać całe pliki
Masz raport na 30 stron i chcesz podsumowanie jednego rozdziału? Nie wklejaj całości. Wklej ten rozdział lub kluczowe fragmenty i powiedz modelowi, co Cię interesuje.
Claude potrafi pracować z plikami, ale to nie znaczy, że zawsze powinien dostawać wszystko. Wyobraź sobie, że prosisz kolegę o opinię na temat jednego akapitu, ale najpierw każesz mu przeczytać całą książkę. Efekt? Zmęczony kolega i ogólnikowa odpowiedź.
To samo robi model, kiedy zasypiesz go danymi.
Pisz prompt jak komendy w wojsku, nie jak listy do babci
Porównaj te dwa podejścia:
Podejście A (spalanie kontekstu):
"Hej, mam taki problem, nie wiem czy mi pomożesz, ale chodzi o to, że mam bazę danych w SQL Server i tam jest tabela z zamówieniami i chciałbym jakoś policzyć ile zamówień było w każdym miesiącu, ale tylko te które mają status 'completed', i jeszcze żeby to było posortowane od najnowszych, i nie wiem czy to ma być GROUP BY czy coś innego, możesz pomóc? Z góry serdecznie dziękuję, jesteś super."
Podejście B (inwestowanie kontekstu):
"SQL Server. Tabela
Ordersz kolumnamiorder_date,status. Napisz query: liczba zamówień miesięcznie, filtrstatus = 'completed', sortowanie DESC po dacie."
Oba pytania dadzą podobną odpowiedź. Ale podejście B zużywa trzy razy mniej tokenów i - co ważniejsze - daje modelowi mniej szumu do przetworzenia. Czysty sygnał, czysta odpowiedź. I na miłość boską, nie dziękuj LLM'owi! No! Dzięki, że posłuchałeś.
Technika "podsumuj i kontynuuj"
Długie konwersacje są czasem nieuniknione. Ale możesz je odchudzić. Kiedy czujesz, że czat robi się ciężki, napisz:
"Podsumuj dotychczasowe ustalenia w 5 punktach. W następnej wiadomości kontynuuję na bazie tego podsumowania."
Potem otwórz nowy czat, wklej podsumowanie i jedź dalej. Kontekst jest świeży, model jest skupiony, a ty nie trafiłeś w limit.
Nie każ modelowi zgadywać
Im więcej modelu zmuszasz do domyślania się, co masz na myśli, tym więcej tokenów leci na wyjaśnienia, dopytywanie i powtórki.
Zamiast: "Zrób mi ładną prezentację o AI" Napisz: "Prezentacja PPTX, 8 slajdów, temat: wdrożenie AI w badaniach rynkowych. Odbiorcy: zarząd firmy badawczej. Ton: profesjonalny, bez buzzwordów. Struktura: problem, rozwiązanie, case study, ROI, następne kroki."
Pierwsze zapytanie generuje rundę pytań zwrotnych (zjadających kontekst) albo prezentację, która nie trafia w to, czego potrzebujesz (co wymaga kolejnych rund poprawek, też zjadających kontekst).
Drugie zapytanie daje gotowy wynik za pierwszym razem.
Formatuj dane wejściowe
Jeśli dajesz modelowi dane do analizy, nie wklejaj ich jako ciągły tekst. Użyj CSV, JSON, markdown - czegokolwiek, co ma strukturę. Model parsuje ustrukturyzowane dane szybciej i dokładniej, a ty zużywasz mniej tokenów na wyjaśnianie, co jest czym.
Przykład: tabela z pięcioma kolumnami w formacie CSV zajmie mniej tokenów niż te same dane opisane słownie.
Używaj system promptów i projektów
Jeśli codziennie robisz podobne rzeczy - pisanie w określonym stylu, analiza danych, generowanie kodu w konkretnym stacku - nie powtarzaj kontekstu za każdym razem.
W Claude.ai masz Projects, gdzie możesz ustawić instrukcje systemowe raz, a potem każdy nowy czat w projekcie startuje z tym kontekstem "za darmo" (nie liczy się do limitu wiadomości, choć liczy się do okna kontekstowego). To jak różnica między tłumaczeniem się od zera każdemu nowemu pracownikowi a spisaniem onboardingu.
Masz stały zestaw wytycznych? Wrzuć go do projektu. Masz dokumentację API, z którą pracujesz codziennie? Wrzuć ją do projektu. Kontekst, który podajesz raz, jest tańszy niż kontekst, który wklejasz dwadzieścia razy.
Podsumowanie dla niecierpliwych
Pięć rzeczy, które zmniejszą zużycie kontekstu i poprawią jakość odpowiedzi:
- Nowe zadanie = nowy czat
- Wklejaj tylko to, co potrzebne, nie całe pliki
- Pisz zwięźle i konkretnie, jak brief, nie jak esej
- Używaj projektów do powtarzalnego kontekstu
- Przy długich sesjach - podsumuj i zacznij od nowa
To nie jest kwestia oszczędności dla samej oszczędności. Chodzi o to, że model, który dostaje czysty, skoncentrowany kontekst, po prostu lepiej pracuje. Mniej szumu, lepsza odpowiedź. Mniejsze zużycie, więcej zapytań w ciągu dnia.
Traktuj kontekst jak budżet. Wydawaj go tam, gdzie daje zwrot.

